What is the MoDaPo?
Download
GitHub - immunoodle/data-portal
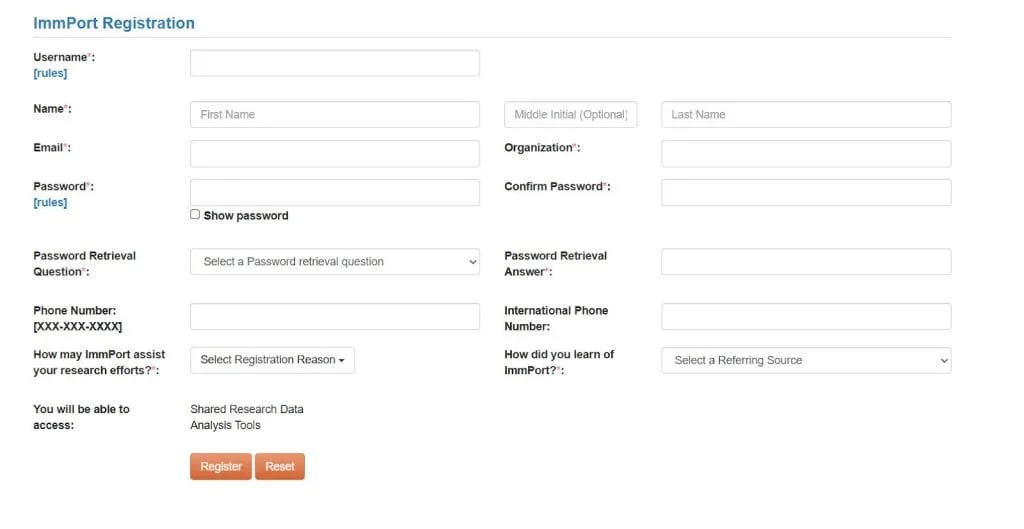
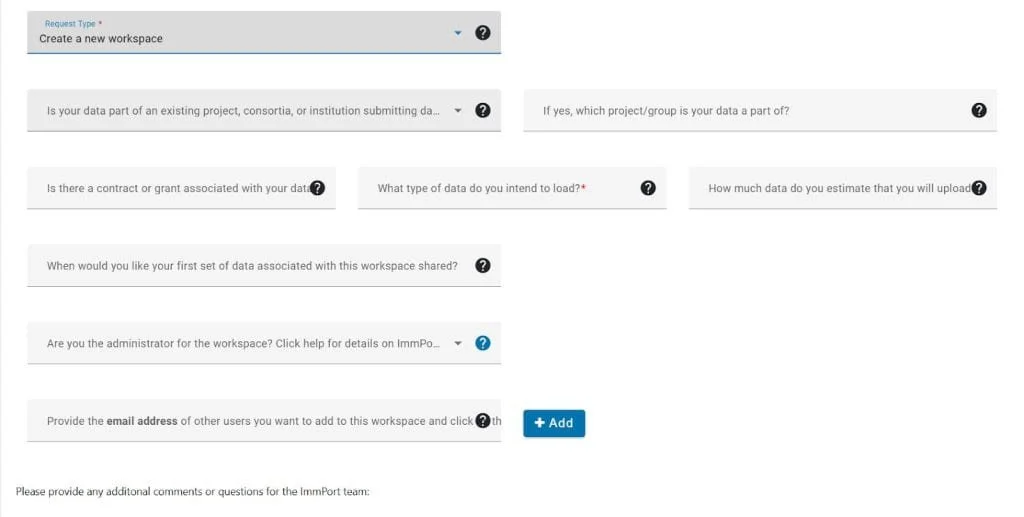
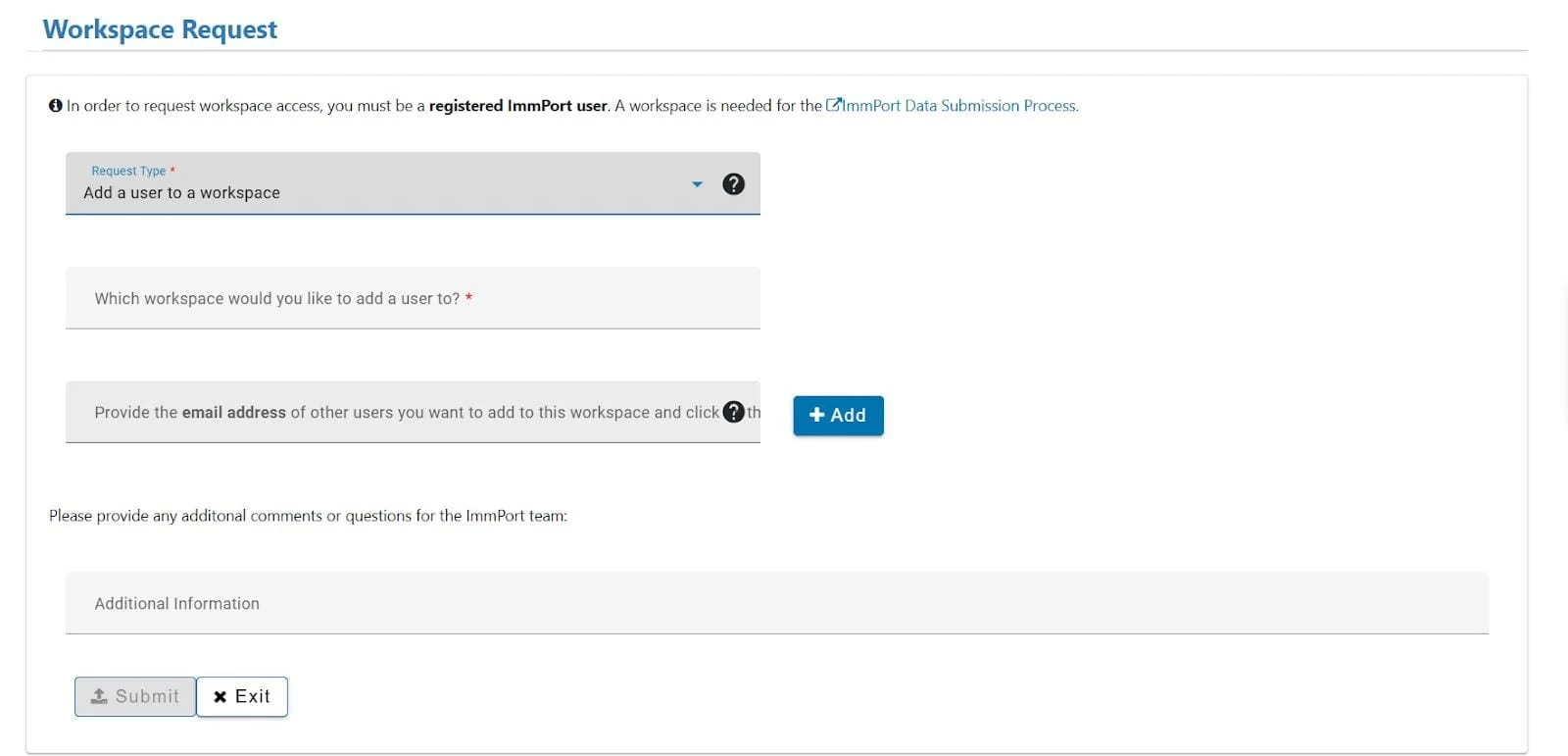
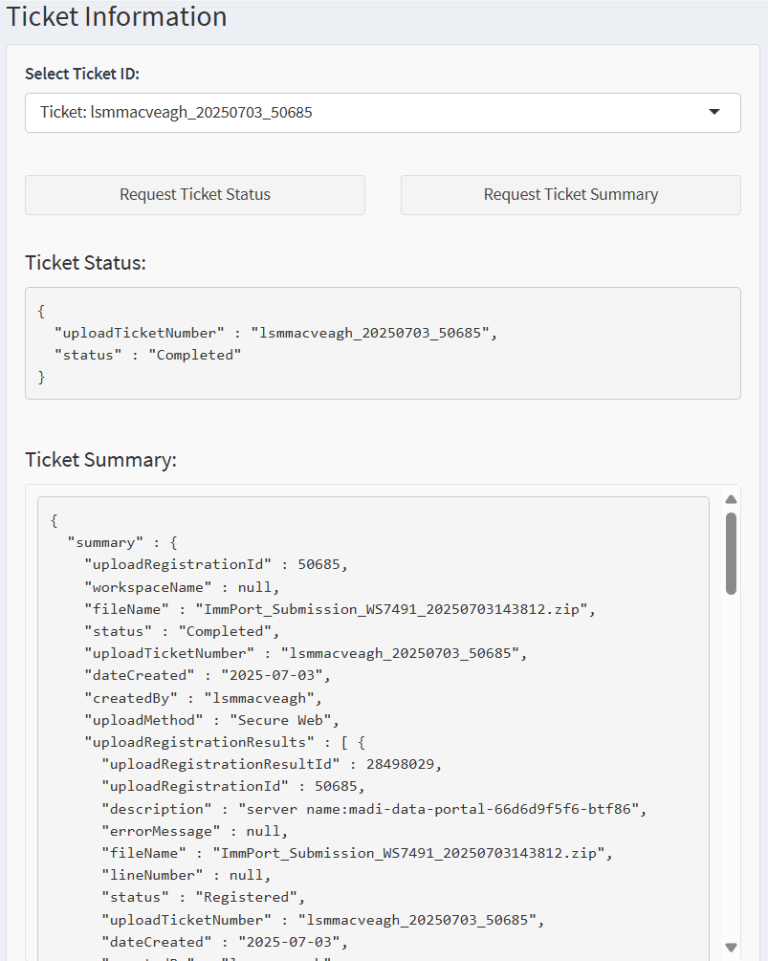
The Mobile Data Portal (MoDaPo) s a tool to seamlessly integrate data sharing into research projects. The integrated workflow system of the MoDaPo addresses the complex challenge of transforming research database content into ImmPort-compliant submissions through a three-layer architecture that separates concerns while maintaining data integrity throughout the pipeline. The system is built around the official ImmPort data model and incorporates the requirements specified in the ImmPort Data Management and Sharing Plan template.
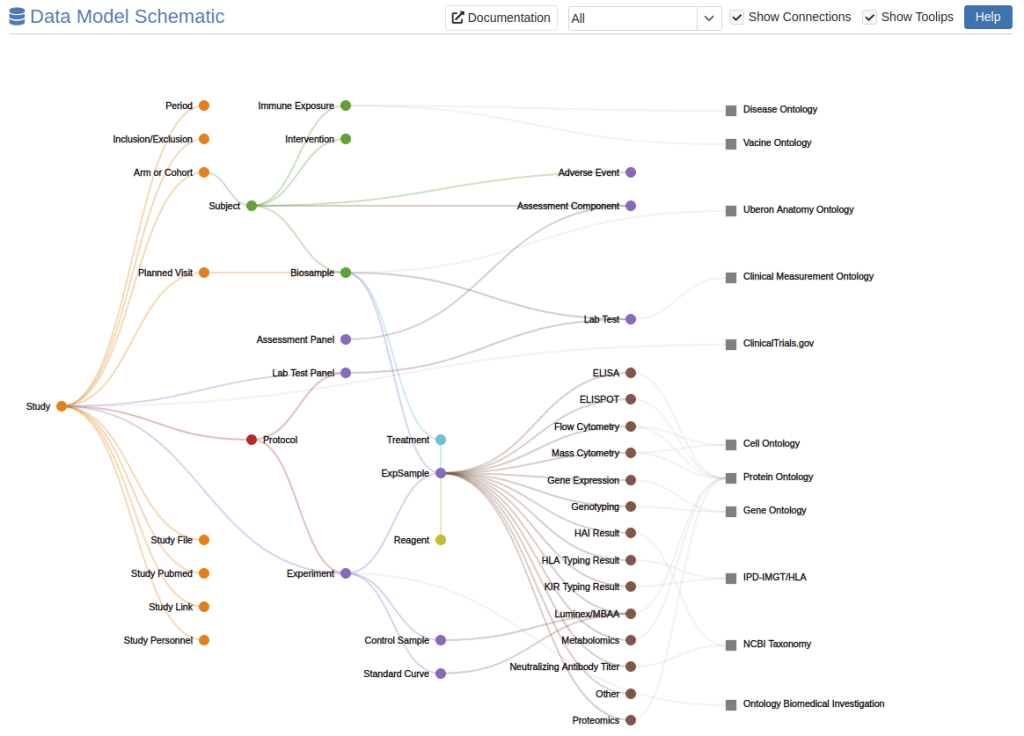
Figure: ImmPort Data Model
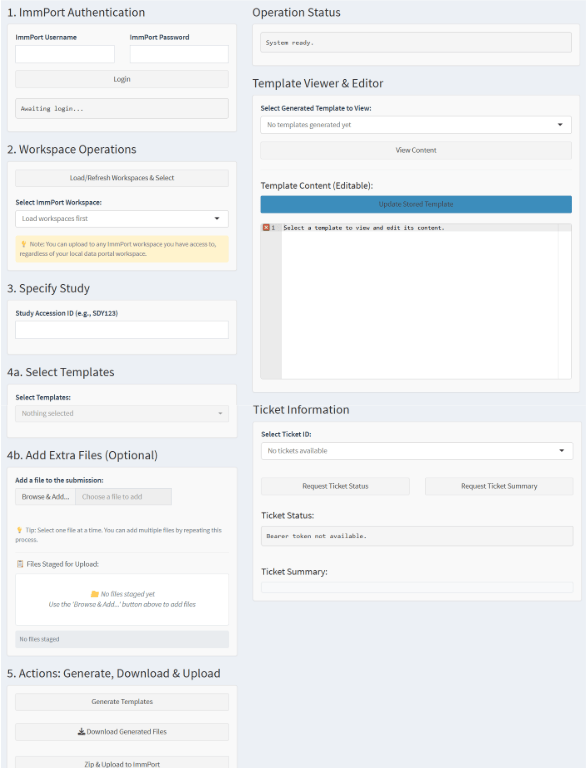
The three primary layers that form a complete data processing pipeline are:
Data Extraction Layer (Python): Handles database connectivity, query execution, and initial data transformation into intermediate formats
Transformation and Curation Layer (R Shiny): Provides interactive data processing, validation, human-in-the-loop curation, and submission preparation
Submission Layer (API Integration): Manages authentication, file upload orchestration, and real-time submission status tracking
The data extraction layer implements a sophisticated database abstraction. The implementation is built primarily in Python, leveraging production-grade libraries including psycopg2-binary for PostgreSQL connectivity, python-dotenv for secure configuration management, and custom connection pooling for high-throughput operations. The system currently supports PostgreSQL databases with a plugin architecture designed for extension to other database management systems including MySQL, Oracle, and cloud-based solutions.
The architecture implements several key design principles:
Modularity: The system is decomposed into distinct, loosely-coupled components that can be developed, tested, and deployed independently, enabling maintenance and extension without affecting other system components.
Data Integrity: Every transformation step maintains complete audit trails and implements validation checkpoints to ensure data consistency from source database to final repository submission.
Extensibility: The plugin-based architecture supports easy addition of new data sources, transformation rules, and target repositories beyond ImmPort.
User-centric Design: The system provides intuitive interfaces for both technical and non technical users, recognizing the diverse skill sets within research teams while maintaining sophisticated functionality for power users.
Compliance-First Approach: All transformation logic is explicitly designed around ImmPort’s official schema requirements and validation rules, ensuring submissions meet repository standards before upload.
Database connections are established using environment-based configuration with encrypted credential storage, ensuring no sensitive information is embedded in source code. The system supports connection pooling and automatic retry logic for production reliability.
The system supports flexible deployment configurations designed for various institutional environments from single-user installations to multi-user production deployments. Multiple simultaneous database connections can be configured, supporting complex research environments with federated data sources or multiple study databases.